

The biggest misconception since the launch of GDPR is the belief the European legislation, published in May 2018, changed the landscape of privacy and security. However, what it actually did was set more stringent checks on the preexisting legal processes and privacy compliance, as well as increase the level of accountability through heftier penalty charges for those noncompliant.
So, how do we manage data and connect data sources safely without fear of handling the personal data of our customers and respondents in a careless manner?
We should start by stating the obvious concept of anonymisation.
Anonymisation VS Pseduonymisation
If I give you a list of gender and age answers from a data set, there is no action you can take or direct link to an individual. You cannot contact the person or determine who they are. The data is anonymous.
M 18
F 56
F 24
M 31
M 31
However, if you look at the bottom two cases, you cannot distinguish them separately, especially in larger data volumes. So how can you ensure you are handling records uniquely if you cannot expose the individuals?
This is where pseudonymization comes in: the act of creating a unique identifier which allows you to differentiate individuals within the data set but not beyond. Another way to think of this is that it is a method used to substitute identifiable data with a reversible, consistent value.
Table A available to the data processor:
1111 M 18
2222 F 56
3333 F 24
4444 M 31
5555 M 31
The data controller will have a way to reverse the unique identifier if needed and to link it up to personal data. Such a table may look like the below.
Table B available to the data controller:
John 1111
Frank 2222
Carol 3333
Rick 4444
Lesley 5555
However, the data processor will not (and should not) have access to Table B, so the identifiers becomes irreversible for the data processor (the party receiving and analysing the data set).
The GDPR Triangle
If you follow GDPR legislation, you’ve likely heard the terms “Data Processor” and “Data Controller”, in addition to many others. Complex systems need simplicity, and the best way to understand what is safe to do when connecting data is through the Triangle Analogy. Here’s how it works…
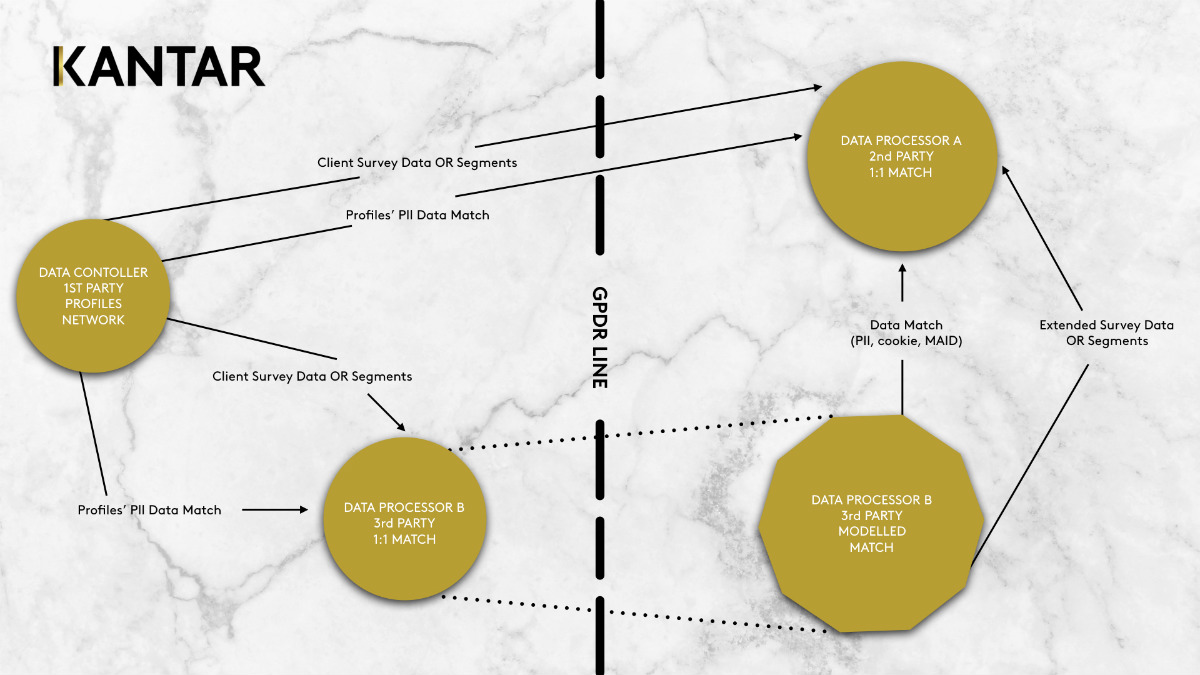
Data Processor A received an pseudonymized data set from the Data Controller, and Data Processor A would like to connect it to their own second-party data at the individual level. The Data Controller holds first-party data and has the means to match and connect the data at individual level.
Firstly, I should be clear that any Data Controller who owns first-party data needs to have a legal agreement in place with the Data Processor involved. You cannot transfer any data or use it to connect without an agreement in place.
Secondly, there are two paths which clearly define whether re-identification is possible or not:
- If you look at the first path, the first-party data sent over is crossing the GDPR line for the connection to happen. If this happens, then re-identification is inevitable, regardless on how secure Data Processor A’s systems are. Consent needs to be in place where individuals have been informed. It is not just about re-identification but also about documenting storage and security.
- Third-party data players can act as intermediaries. They have means to match with no intentions of holding any data, which is the sole purpose they were hired for. Their primary role is to model data and use “lookalike” logic, to leverage their data at scale. Data Processor B can then match to Data Processor A without Data Controller's data ever being exposed or transferred beyond the GDPR line.
Both paths must ensure consent is recorded either explicitly or via agreed terms and conditions.
Privacy Policy and Explicit Consent
It is yours and everyone else's duty to know what the current terms and conditions are for using your customer or individuals’ personal data.
Terms and conditions, as well as privacy policies, set the framework on which businesses can operate and specify how individuals’ data can be used. They require data to be protected, but they also alleviate the steps required to obtain customer’s permission or consent, so long as the consent given is freely-given, specific, informed and revocable. By agreeing to terms and conditions, individuals opt-in in to the business mechanisms laid out to process, manage and use their personal data.
Every scenario or use case that falls outside the above-mentioned framework means the individual never agreed and, therefore, explicit consent is required (you will need to contact the individual and explain in detail how you will use their data). They will opt-in then and there which we will call an ‘ad hoc opt-in,’ and this is only valid for that specific use case at that specific point in time.
Using data without permission can lead to a ‘data incident’ or data breach.
Data Incident VS Data Breach
You hear the two definitions above interchangeably in the news, but they are different.
A data incident is the involuntary or careless act of leaving personal data exposed out of human negligence. Examples range from leaving email addresses in a text file on a public computer, to transferring email addresses from server to server without hiding it through encryption or password-protection.
A data breach instead is the intentional act of stealing individuals’ personal data for illicit reasons and through the use of unlawful methods. Most data hacks usually come from external players trying to bring down a website or break any security put in place.
Hash Encryption is Secure, Right?
There are many secure options out there when it comes to storing and transferring sensitive data. However, it’s important to recognize that “fully safe” doesn’t always mean “fully compliant” when it comes to security.
The first thing in data storage and data transfers is understanding the data, not just where it lives, but also its classification and the controls and policies that must be in place and prioritized. Data security not only involves deploying the right data security mechanisms, but also combining people and processes with the technology we use to protect data throughout its lifecycle.
Security is always a combination of the 3 points below:
- Storage and Transfer
- Transferring and storing data is not just about protecting your file with a password. It is also a matter of knowing where you are sending the data (whether it is an encrypted network or not) and how you are sharing instructions to access it (whether over the phone, via encryption keys or some other method).
- Any weak points along the way where someone can intercept your transfer and storage increases the security risks. But how can I be sure what is considered safe?
- Data Reversibility
- Encrypting data with widely used hashing cryptography is not enough and does not hide your sensitive data. It simply adds an additional step, which anyone can recreate while still being able to match personal data or identify individuals.
- The safest options are irreversible matches, but you may still need to link back data somehow. Think about pseudonymization. You may need to store data somewhere else to help those with approval link the data back together. Doesn't that lead to data reversibility?
- Legal Agreement
- Any creation, transfer and storage of personal / health / sensitive data should be covered by an agreement between the parties exchanging the data, so that any legal risks are "transferred" to the other party and vice-versa. (If in doubt discuss with your legal/privacy resource).
- Agreements work in combination with the previous two points (storage and reversibility) without the burden of feeling inadequate or not having enough knowledge on the security technology out there and ensures a human touch on mutual understanding is put against the use of data.